
Platform Engineering Transformation at OutSystems
We Trusted Kubernetes with Our Infrastructure But We Didn't Trust Developers With The Deploy Button

I was invited to speak at Chainguard Assemble 2026 in New York City, together with João Brandão, Release Engineering Director at OutSystems, to share a story that I believe many teams will recognize.
Breaking the Release Monolith
At OutSystems, releasing software had become… harder than building it. Which is slightly embarrassing when you think about it.
Because technically, we were doing everything right. We had microservices, Kubernetes, and a fully cloud-native architecture. Teams were moving fast, writing code, shipping features.
And then everything stopped at the release stage.
BC: Before Cloud - The Good Old Days
For a bit of context, this didn’t come out of nowhere.
For two decades, we lived in what I like to call the BC: Before Cloud era. We had a monolith, a handful of releases per year, and customers installing software in their own environments. Stability mattered more than speed, and it worked really well. We live a pretty comfortable life.

Then the Cloud Happened
Then the cloud arrived, and we did what everyone did - we modernized. New architecture, new platform, new possibilities. Microservices everywhere, cloud-native product.
But we kept one thing unchanged: how we released software.

Every team still had to board the same synchronized release train. What was tested in staging had to be exactly what went to production. OutSystems wanted predictability, safety, and control.
Which, as we realized, meant one thing: delay.
We didn’t have a deployment problem. We had a trust problem - we realized we didn’t trust the teams with autonomous deployments, and the teams didn’t trust each other with full test coverage either.
And as you can imagine, we had a couple of more challenges with the release train too.
Breaking things
The result was that everyone was blocked by everyone. Release Train schedules felt like train station timetables in the ‘90s - the trains were either delayed or canceled. Bake/soak times were used as a throttle, not a signal.
Infra changes were resetting bake periods endlessly.
And on top of this, the release team got reduced to Ticket Ops - professional queue managers.
We found ourselves having fast tracks everywhere, which is another way of saying “chaos”. And on top of it we faced on-call fatigue, especially for the release teams.
The metrics weren’t impressive either. At OutSystems we wanted safety but also expected speed. We could deliver quickly with this setup.
Lead time took from 4 days to 4 weeks. Very far from DORA elite. And on top of it, Developer Experience surveys showed that the release cycle was the #1 pain point as reported by developers.

The Decision
At some point, it became obvious that no amount of optimization would fix this. So we had to do the uncomfortable thing - we decided it was high time that we broke the release train.
We needed to move from blockers to enablers and enter the Platform Engineering mindset.
Pegasus Emerged - Our CD Platform

This is where Pegasus comes in, our internal continuous delivery platform, built by Platform Engineering and treated like a product, not a gate.
The idea wasn’t revolutionary, but the execution mattered.
Instead of coordinating releases, we decoupled them. Teams could deploy independently, on their own terms. Security, compliance, and quality weren’t enforced through meetings or documentation, but directly in the platform, as code.
No release calendars.
No ticket ops.
And most importantly, no begging!
One of my favorite principles from this journey still makes me smile:

Adoption is an Initiative on Its Own
One thing became very clear along the way: in platform engineering, building the platform was only half the job. Adoption has become a whole separate initiative.
As a Technical Program Manager, my role isn’t just to deliver “the thing.” It’s to make sure the value is understood, the goal is achieved, and, most importantly, that people actually use it. Because it isn’t a mandate anymore.
Platform Engineering creates a mindset shift. It’s like injecting product thinking into hardcore engineering. We build internal platforms, but we treat them like products. And the product teams become our customers, not people we control or boss around. Which means adoption has to be earned.
So I went on looking for champions who will first onboard their services on the shiny new CD platform. The idea was simple: let them lead by example and become Pegasus ambassadors.
Of course, it wasn’t all smooth sailing. At one point, I realized something uncomfortable: teams didn’t trust each other’s test coverage. So we had to address it.
We brought in the Quality team and created a Community of Practice. Team Leads working on key customer journeys sat down together (yes, actual humans, in meetings) and defined a shared testing strategy. The goal was simple: create enough confidence so teams could release autonomously without the constant fear of breaking everything.
It took weeks. There were debates. Doubts. Probably a few “this will never work” moments. But slowly, something started to shift.
One by one, microservices moved onto Pegasus. And with each one, the experience got better. Releases stopped being a hurdle and started feeling like what continuous deployment was supposed to be all along.
Metrics Tell The Success Story
With the new developments in the release area, the lead time dropped to under 24 hours. Teams went from weekly releases to dozens per day. We crossed 1,000 deployments per month and reached Elite DORA performance.
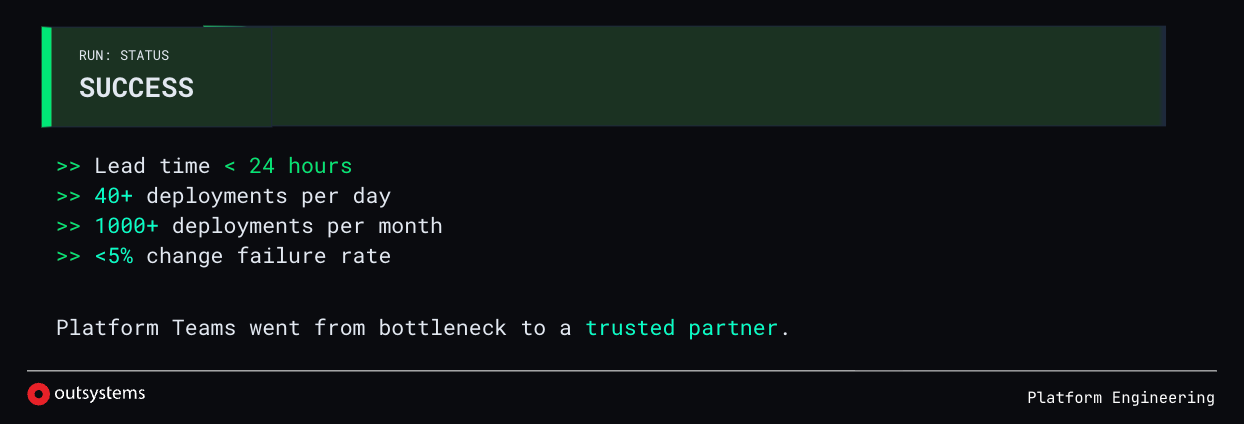
But more importantly, something shifted culturally. Platform Engineering stopped being seen as a bottleneck and started to be seen as a partner.
Because we stopped controlling teams, and started enabling them.
A Lesson in Trust
There was one big lesson in all of this. You can’t automate your way out of a trust problem. We had tried that, and it doesn’t work.
Trust has to be built into the system itself. Into the way releases happen, into the guardrails and into the feedback loops.
And equally important, speed without safety is just a faster way to break things.
So Pegasus was never just about automation. It was about creating a system where teams have autonomy, but within boundaries that keep everything reliable.
An Agentic Future
Now that releases are no longer painful, we’ve started asking a dangerous question: How do we make them boring?
This is where things get interesting again.
We’re evolving Pegasus into a more agentic platform, where the system doesn’t just execute steps, but starts to make informed decisions. Detecting failures, suggesting root causes, and evaluating whether it’s safe to promote a release.
Less “deploy and hope.” More “the system already knows if this makes sense.”
It’s a shift from automation to judgment.

Looking back, breaking the release monolith wasn’t really about pipelines, tools, or even architecture. It was about trust.
And once we encoded that trust into the platform, everything accelerated.